Superviser un serveur HAproxy avec Zabbix
Après avoir monté le cluster MariaDB Galera et placé un serveur HAproxy en frontal, il me restait encore à mettre en place la supervision de ce cluster. Je voulais notamment, en dehors de la supervision de base qu'on peut déployer sur un serveur (classiquement processeurs / RAM / disques / Réseau) pouvoir visualiser …
Après avoir monté le cluster MariaDB Galera et placé un serveur HAproxy en frontal, il me restait encore à mettre en place la supervision de ce cluster. Je voulais notamment, en dehors de la supervision de base qu'on peut déployer sur un serveur (classiquement processeurs / RAM / disques / Réseau) pouvoir visualiser l'état du cluster rapidement.
Je me suis lancé dans la recherche d'un template Zabbix déjà existant pour superviser HAproxy mais je n'ai rien trouvé de convainquant. Je me suis décidé à écrire mon propre template et donc le script qui va avec.
Avant d'utiliser ce script, il faut activer les stats dans le fichiers de configuration d'HAproxy dans la section [global]
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
Le script Python va ensuite lire les données en communiquant avec le socket d'HAproxy directement et retourner la statistique demandée pour le couple frontend/serveur.
Voici le script.
#! /usr/bin/python
import subprocess
import itertools
import json
import sys
req = ""
if len(sys.argv) == 2:
req = sys.argv[1]
if len(sys.argv) == 4:
px = sys.argv[1]
sv = sys.argv[2]
queryStat = sys.argv[3]
if len(sys.argv) != 2 and len(sys.argv) != 4:
print "Usage: run script with one or three arguments\nOne argument: \n discovery : json output of discovered pxname and svname \n\nThree arguments:\n pxname : pxname in which you want to process the stat\n svname : svname in the pxname in which you want to process the stat\n stat : stat you want to query for pxname,svname"
sys.exit(1)
allstats = subprocess.Popen('echo "show stat" | socat /var/lib/haproxy/stats stdio', shell=True, stdout=subprocess.PIPE).communicate()[0]
if req == "discovery":
haDiscovery = []
for myLine in allstats.splitlines()[1:-1]:
lineStats = myLine.split(',')
pxname = lineStats[0]
svname = lineStats[1]
haDiscovery.append({'{#PXNAME}' : pxname, '{#SVNAME}' : svname})
print json.dumps({ "data": haDiscovery})
sys.exit()
statNameList = allstats.splitlines()[0][2:-1].split(',')
monDico = {}
for myLine in allstats.splitlines()[1:-1]:
statList = myLine.split(',')
if px == statList[0] and sv == statList[1]:
monDico = dict(itertools.izip(statNameList,statList))
print monDico[queryStat]
Une fois toutes ces métriques récupérées, j'ai pu construire un dashboard Grafana afin d'avoir rapidement sous les yeux l'état général du cluster.
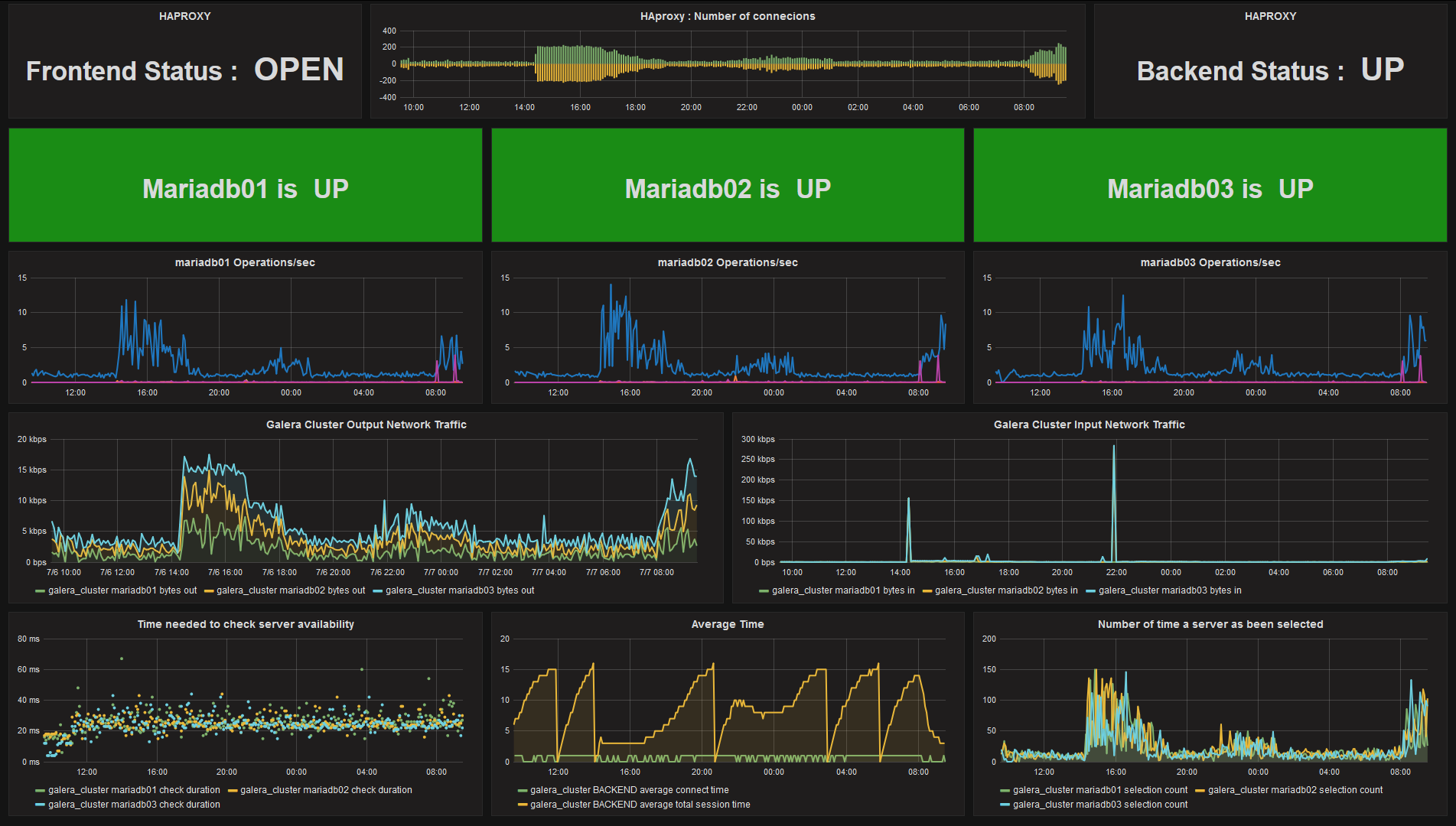
Le script, le template Zabbix et le fichier de paramétrage de l'agent sont disponible sur Github